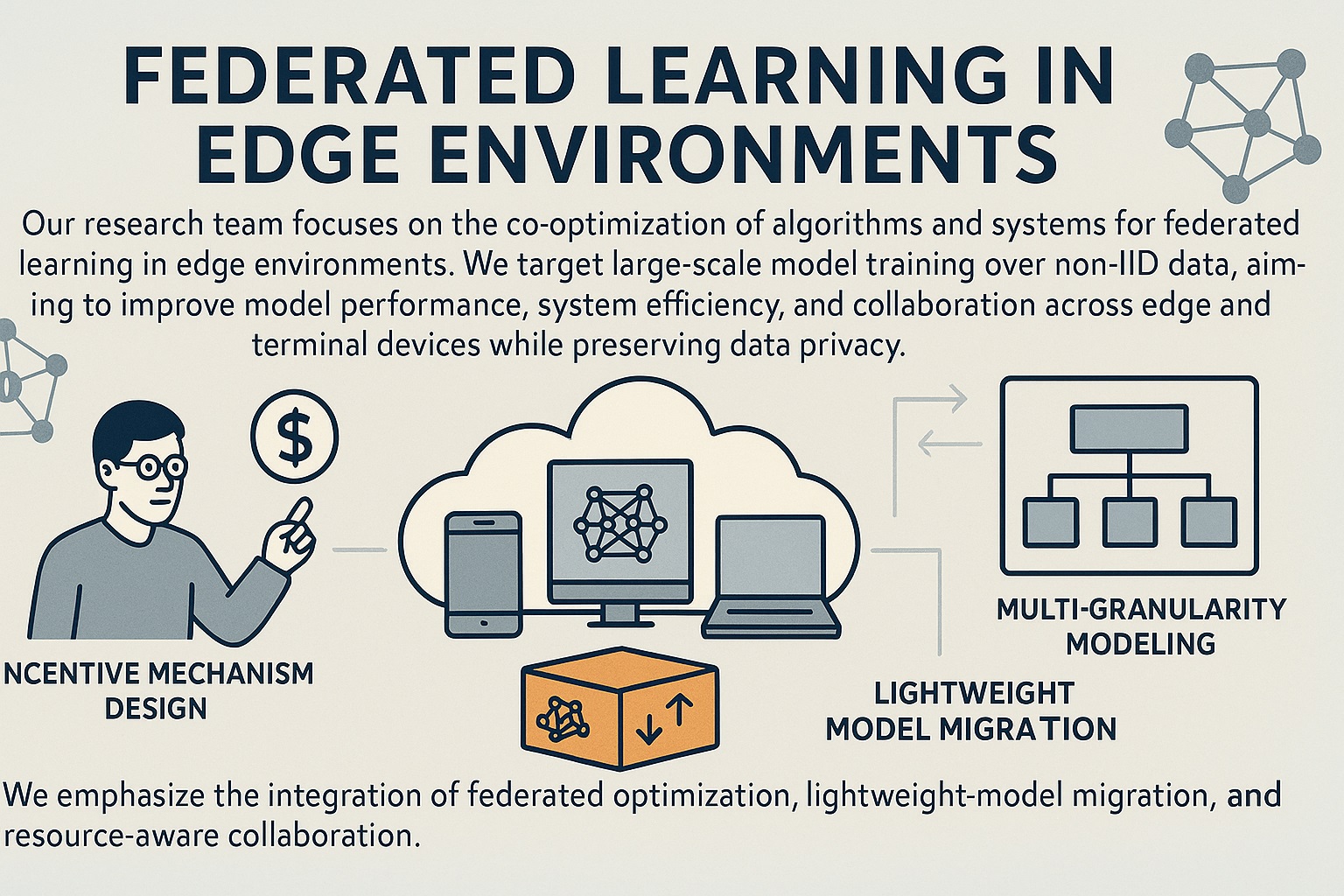
Our research team focuses on the co-optimization of algorithms and systems for federated learning in edge environments. We target large-scale model training over non-IID data, aiming to improve model performance, system efficiency, and collaboration across edge and terminal devices while preserving data privacy. Our work includes incentive mechanism design, multi-granularity personalized modeling, and adaptation for heterogeneous devices. We emphasize the integration of federated optimization, lightweight model migration, and resource-aware collaboration. (1) In practical applications, we propose personalized federated learning and multi-granularity knowledge distillation for distributed modeling in power systems. By leveraging similar data on edge devices, we improve model perception and support adaptive training on resource-constrained terminals. (2) On the theoretical side, we introduce multi-granularity data modeling and a hierarchical cloud-edge-terminal architecture. This helps address the heterogeneity in data, models, and devices, enabling more efficient coordination. Our research is supported by major national and industrial projects. We have collaborated with organizations like State Grid and Tianjin Mobile, applying our methods to smart grid diagnostics and privacy-aware knowledge transfer. With support from the National Natural Science Foundation and other programs, we have validated our work on real-world datasets and prototype systems. The results offer practical solutions to key challenges in privacy-preserving modeling and cross-device collaboration, promoting real-world deployment of federated intelligence.