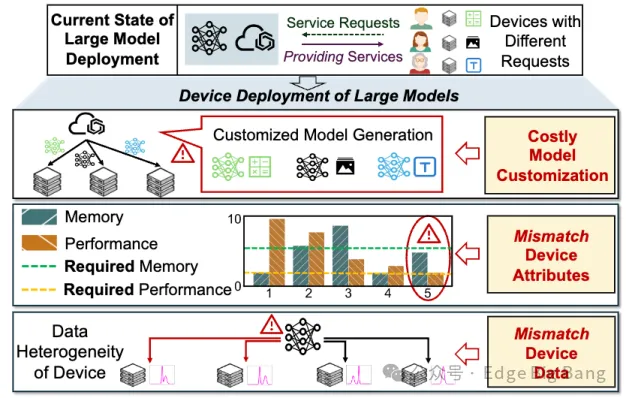
在智能终端日益普及的今天,如何让大模型真正“跑”进边缘设备,成为学术界和工业界共同关注的焦点问题。在这一关键技术转折点上,天津大学Edge Big Bang Group持续发力,探索大模型在分布式环境下的高效部署路径。近日,课题组在国际分布式计算领域顶级会议IEEE ICDCS 2025上发表最新成果,提出了名为ACME的模型定制方法。该方法通过构建“双向单循环”系统架构,突破传统集中式部署瓶颈,在性能、能耗与模型个性化之间实现精巧平衡,展现出将Transformer大模型与异构设备深度融合的全新可能。
IEEE International Conference on Distributed Computing Systems(ICDCS)是分布式计算领域最重要的国际学术会议之一,聚焦于系统、算法与应用的前沿研究,CCF-B,长期被视为该领域的顶级会议。实验室的硕士生戴子明的论文《ACME: Adaptive Customization of Large Models via Distributed Systems》被 IEEE ICDCS 2025录用。
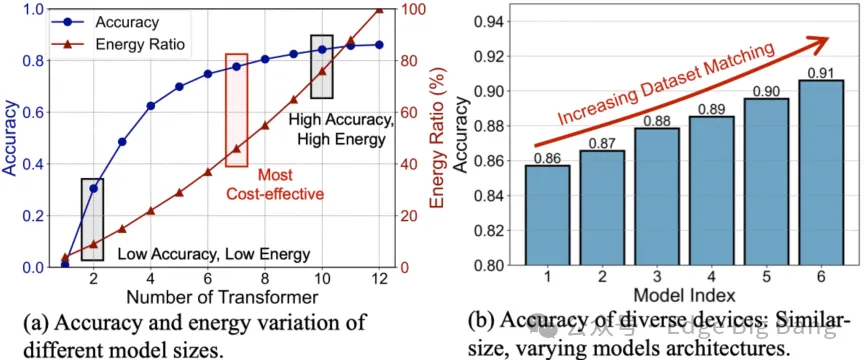
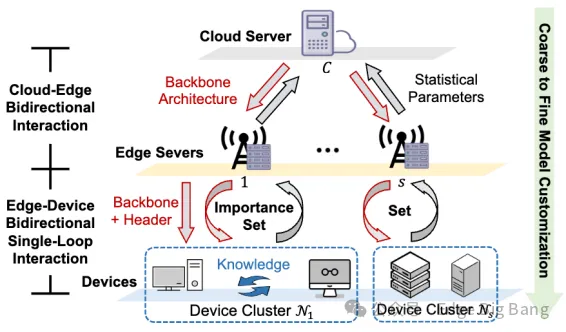
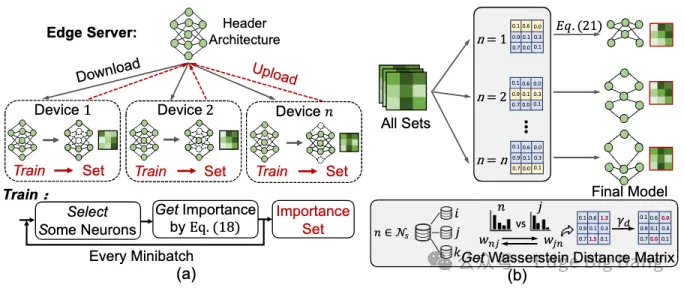
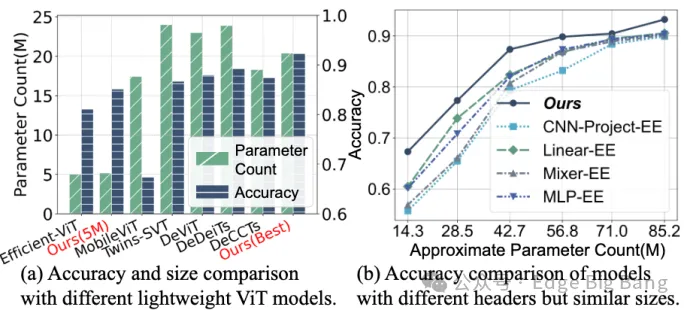
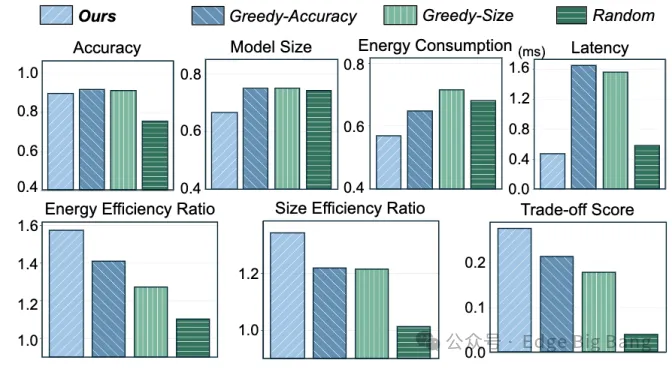
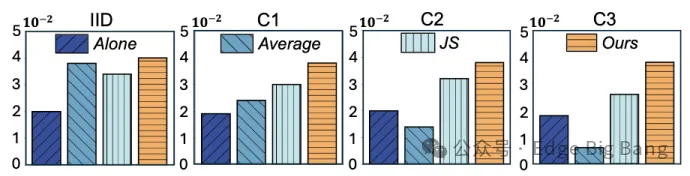
为此,我们提出了一个全新的大模型定制框架——Adaptive Customization Approach of Transformer-based Large Models (ACME),其核心在于通过分布式系统协同完成模型从“骨干”到“头部”的渐进式定制,兼顾设备约束与数据特征,真正实现面向设备的个性化模型架构优化。
Ziming Dai, Chao Qiu, Fei Gao, Yunfeng Zhao, and Xiaofei Wang. “ACME: Adaptive Customization of Large Models via Distributed Systems.” In Proceedings of the 45th IEEE International Conference on Distributed Computing Systems (ICDCS), 2025. (CCF-B)
本项工作的顺利发表,离不开课题组老师们的前瞻指导与同学们的持续投入。从系统架构设计到算法落地实施,每一步都凝聚了团队对边缘智能前沿问题的深入思考与技术攻坚。我们也由衷感谢每一位在实验调试、模型验证与论文撰写中默默付出的成员,正是大家的协同努力,才让ACME得以最终呈现在国际舞台。未来,Edge Big Bang Group将继续聚焦“智能算力边界”的关键挑战,在大模型轻量化、分布式推理与个性化定制等方向持续探索。欢迎大家关注我们的更多进展,也期待与各界有志之士在科研的道路上携手前行,共同拓展边缘智能的无限可能!